 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio Temporal Action Localization
Papers and Code
Score-Based Change-Point Detection and Region Localization for Spatio-Temporal Point Processes
Feb 04, 2026We study sequential change-point detection for spatio-temporal point processes, where actionable detection requires not only identifying when a distributional change occurs but also localizing where it manifests in space. While classical quickest change detection methods provide strong guarantees on detection delay and false-alarm rates, existing approaches for point-process data predominantly focus on temporal changes and do not explicitly infer affected spatial regions. We propose a likelihood-free, score-based detection framework that jointly estimates the change time and the change region in continuous space-time without assuming parametric knowledge of the pre- or post-change dynamics. The method leverages a localized and conditionally weighted Hyvärinen score to quantify event-level deviations from nominal behavior and aggregates these scores using a spatio-temporal CUSUM-type statistic over a prescribed class of spatial regions. Operating sequentially, the procedure outputs both a stopping time and an estimated change region, enabling real-time detection with spatial interpretability. We establish theoretical guarantees on false-alarm control, detection delay, and spatial localization accuracy, and demonstrate the effectiveness of the proposed approach through simulations and real-world spatio-temporal event data.
DETACH : Decomposed Spatio-Temporal Alignment for Exocentric Video and Ambient Sensors with Staged Learning
Dec 23, 2025



Aligning egocentric video with wearable sensors have shown promise for human action recognition, but face practical limitations in user discomfort, privacy concerns, and scalability. We explore exocentric video with ambient sensors as a non-intrusive, scalable alternative. While prior egocentric-wearable works predominantly adopt Global Alignment by encoding entire sequences into unified representations, this approach fails in exocentric-ambient settings due to two problems: (P1) inability to capture local details such as subtle motions, and (P2) over-reliance on modality-invariant temporal patterns, causing misalignment between actions sharing similar temporal patterns with different spatio-semantic contexts. To resolve these problems, we propose DETACH, a decomposed spatio-temporal framework. This explicit decomposition preserves local details, while our novel sensor-spatial features discovered via online clustering provide semantic grounding for context-aware alignment. To align the decomposed features, our two-stage approach establishes spatial correspondence through mutual supervision, then performs temporal alignment via a spatial-temporal weighted contrastive loss that adaptively handles easy negatives, hard negatives, and false negatives. Comprehensive experiments with downstream tasks on Opportunity++ and HWU-USP datasets demonstrate substantial improvements over adapted egocentric-wearable baselines.
DEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
Nov 14, 2025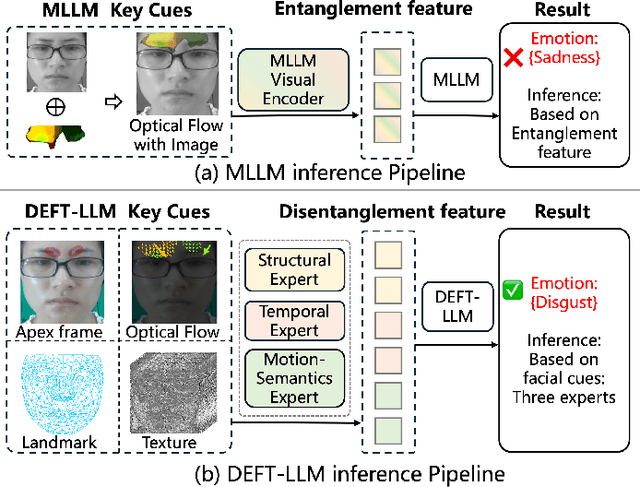
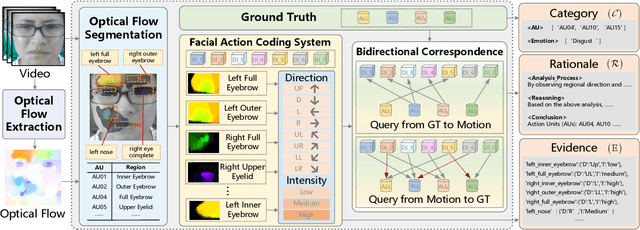
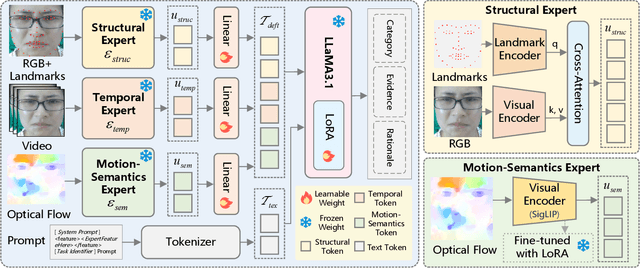
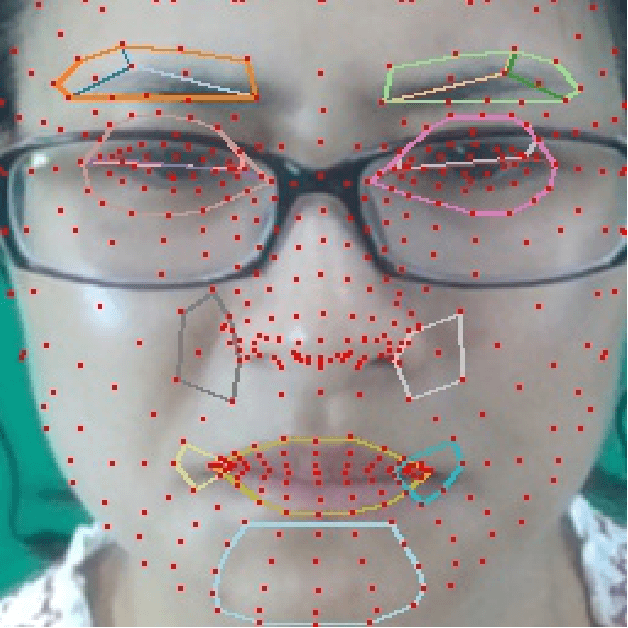
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.
DoGCLR: Dominance-Game Contrastive Learning Network for Skeleton-Based Action Recognition
Nov 19, 2025Existing self-supervised contrastive learning methods for skeleton-based action recognition often process all skeleton regions uniformly, and adopt a first-in-first-out (FIFO) queue to store negative samples, which leads to motion information loss and non-optimal negative sample selection. To address these challenges, this paper proposes Dominance-Game Contrastive Learning network for skeleton-based action Recognition (DoGCLR), a self-supervised framework based on game theory. DoGCLR models the construction of positive and negative samples as a dynamic Dominance Game, where both sample types interact to reach an equilibrium that balances semantic preservation and discriminative strength. Specifically, a spatio-temporal dual weight localization mechanism identifies key motion regions and guides region-wise augmentations to enhance motion diversity while maintaining semantics. In parallel, an entropy-driven dominance strategy manages the memory bank by retaining high entropy (hard) negatives and replacing low-entropy (weak) ones, ensuring consistent exposure to informative contrastive signals. Extensive experiments are conducted on NTU RGB+D and PKU-MMD datasets. On NTU RGB+D 60 X-Sub/X-View, DoGCLR achieves 81.1%/89.4% accuracy, and on NTU RGB+D 120 X-Sub/X-Set, DoGCLR achieves 71.2%/75.5% accuracy, surpassing state-of-the-art methods by 0.1%, 2.7%, 1.1%, and 2.3%, respectively. On PKU-MMD Part I/Part II, DoGCLR performs comparably to the state-of-the-art methods and achieves a 1.9% higher accuracy on Part II, highlighting its strong robustness on more challenging scenarios.
RoboOS-NeXT: A Unified Memory-based Framework for Lifelong, Scalable, and Robust Multi-Robot Collaboration
Oct 30, 2025The proliferation of collaborative robots across diverse tasks and embodiments presents a central challenge: achieving lifelong adaptability, scalable coordination, and robust scheduling in multi-agent systems. Existing approaches, from vision-language-action (VLA) models to hierarchical frameworks, fall short due to their reliance on limited or dividual-agent memory. This fundamentally constrains their ability to learn over long horizons, scale to heterogeneous teams, or recover from failures, highlighting the need for a unified memory representation. To address these limitations, we introduce RoboOS-NeXT, a unified memory-based framework for lifelong, scalable, and robust multi-robot collaboration. At the core of RoboOS-NeXT is the novel Spatio-Temporal-Embodiment Memory (STEM), which integrates spatial scene geometry, temporal event history, and embodiment profiles into a shared representation. This memory-centric design is integrated into a brain-cerebellum framework, where a high-level brain model performs global planning by retrieving and updating STEM, while low-level controllers execute actions locally. This closed loop between cognition, memory, and execution enables dynamic task allocation, fault-tolerant collaboration, and consistent state synchronization. We conduct extensive experiments spanning complex coordination tasks in restaurants, supermarkets, and households. Our results demonstrate that RoboOS-NeXT achieves superior performance across heterogeneous embodiments, validating its effectiveness in enabling lifelong, scalable, and robust multi-robot collaboration. Project website: https://flagopen.github.io/RoboOS/
UTAL-GNN: Unsupervised Temporal Action Localization using Graph Neural Networks
Aug 27, 2025



Fine-grained action localization in untrimmed sports videos presents a significant challenge due to rapid and subtle motion transitions over short durations. Existing supervised and weakly supervised solutions often rely on extensive annotated datasets and high-capacity models, making them computationally intensive and less adaptable to real-world scenarios. In this work, we introduce a lightweight and unsupervised skeleton-based action localization pipeline that leverages spatio-temporal graph neural representations. Our approach pre-trains an Attention-based Spatio-Temporal Graph Convolutional Network (ASTGCN) on a pose-sequence denoising task with blockwise partitions, enabling it to learn intrinsic motion dynamics without any manual labeling. At inference, we define a novel Action Dynamics Metric (ADM), computed directly from low-dimensional ASTGCN embeddings, which detects motion boundaries by identifying inflection points in its curvature profile. Our method achieves a mean Average Precision (mAP) of 82.66% and average localization latency of 29.09 ms on the DSV Diving dataset, matching state-of-the-art supervised performance while maintaining computational efficiency. Furthermore, it generalizes robustly to unseen, in-the-wild diving footage without retraining, demonstrating its practical applicability for lightweight, real-time action analysis systems in embedded or dynamic environments.
Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding
Sep 18, 2025Spatio-temporal video grounding (STVG) aims at localizing the spatio-temporal tube of a video, as specified by the input text query. In this paper, we utilize multimodal large language models (MLLMs) to explore a zero-shot solution in STVG. We reveal two key insights about MLLMs: (1) MLLMs tend to dynamically assign special tokens, referred to as \textit{grounding tokens}, for grounding the text query; and (2) MLLMs often suffer from suboptimal grounding due to the inability to fully integrate the cues in the text query (\textit{e.g.}, attributes, actions) for inference. Based on these insights, we propose a MLLM-based zero-shot framework for STVG, which includes novel decomposed spatio-temporal highlighting (DSTH) and temporal-augmented assembling (TAS) strategies to unleash the reasoning ability of MLLMs. The DSTH strategy first decouples the original query into attribute and action sub-queries for inquiring the existence of the target both spatially and temporally. It then uses a novel logit-guided re-attention (LRA) module to learn latent variables as spatial and temporal prompts, by regularizing token predictions for each sub-query. These prompts highlight attribute and action cues, respectively, directing the model's attention to reliable spatial and temporal related visual regions. In addition, as the spatial grounding by the attribute sub-query should be temporally consistent, we introduce the TAS strategy to assemble the predictions using the original video frames and the temporal-augmented frames as inputs to help improve temporal consistency. We evaluate our method on various MLLMs, and show that it outperforms SOTA methods on three common STVG benchmarks. The code will be available at https://github.com/zaiquanyang/LLaVA_Next_STVG.
Multi-Level LVLM Guidance for Untrimmed Video Action Recognition
Aug 24, 2025Action recognition and localization in complex, untrimmed videos remain a formidable challenge in computer vision, largely due to the limitations of existing methods in capturing fine-grained actions, long-term temporal dependencies, and high-level semantic information from low-level visual features. This paper introduces the Event-Contextualized Video Transformer (ECVT), a novel architecture that leverages the advanced semantic understanding capabilities of Large Vision-Language Models (LVLMs) to bridge this gap. ECVT employs a dual-branch design, comprising a Video Encoding Branch for spatio-temporal feature extraction and a Cross-Modal Guidance Branch. The latter utilizes an LVLM to generate multi-granularity semantic descriptions, including Global Event Prompting for macro-level narrative and Temporal Sub-event Prompting for fine-grained action details. These multi-level textual cues are integrated into the video encoder's learning process through sophisticated mechanisms such as adaptive gating for high-level semantic fusion, cross-modal attention for fine-grained feature refinement, and an event graph module for temporal context calibration. Trained end-to-end with a comprehensive loss function incorporating semantic consistency and temporal calibration terms, ECVT significantly enhances the model's ability to understand video temporal structures and event logic. Extensive experiments on ActivityNet v1.3 and THUMOS14 datasets demonstrate that ECVT achieves state-of-the-art performance, with an average mAP of 40.5% on ActivityNet v1.3 and mAP@0.5 of 67.1% on THUMOS14, outperforming leading baselines.
Hierarchical Multi-Stage Transformer Architecture for Context-Aware Temporal Action Localization
Jul 08, 2025Inspired by the recent success of transformers and multi-stage architectures in video recognition and object detection domains. We thoroughly explore the rich spatio-temporal properties of transformers within a multi-stage architecture paradigm for the temporal action localization (TAL) task. This exploration led to the development of a hierarchical multi-stage transformer architecture called PCL-Former, where each subtask is handled by a dedicated transformer module with a specialized loss function. Specifically, the Proposal-Former identifies candidate segments in an untrimmed video that may contain actions, the Classification-Former classifies the action categories within those segments, and the Localization-Former precisely predicts the temporal boundaries (i.e., start and end) of the action instances. To evaluate the performance of our method, we have conducted extensive experiments on three challenging benchmark datasets: THUMOS-14, ActivityNet-1.3, and HACS Segments. We also conducted detailed ablation experiments to assess the impact of each individual module of our PCL-Former. The obtained quantitative results validate the effectiveness of the proposed PCL-Former, outperforming state-of-the-art TAL approaches by 2.8%, 1.2%, and 4.8% on THUMOS14, ActivityNet-1.3, and HACS datasets, respectively.
UniSTFormer: Unified Spatio-Temporal Lightweight Transformer for Efficient Skeleton-Based Action Recognition
Aug 12, 2025



Skeleton-based action recognition (SAR) has achieved impressive progress with transformer architectures. However, existing methods often rely on complex module compositions and heavy designs, leading to increased parameter counts, high computational costs, and limited scalability. In this paper, we propose a unified spatio-temporal lightweight transformer framework that integrates spatial and temporal modeling within a single attention module, eliminating the need for separate temporal modeling blocks. This approach reduces redundant computations while preserving temporal awareness within the spatial modeling process. Furthermore, we introduce a simplified multi-scale pooling fusion module that combines local and global pooling pathways to enhance the model's ability to capture fine-grained local movements and overarching global motion patterns. Extensive experiments on benchmark datasets demonstrate that our lightweight model achieves a superior balance between accuracy and efficiency, reducing parameter complexity by over 58% and lowering computational cost by over 60% compared to state-of-the-art transformer-based baselines, while maintaining competitive recognition performance.